Modul: Analysieren von Fakten, Strukturen und Verhalten#

Inhalt
Die Untersuchung von Fakten, Strukturen und dem Verhalten personenbezogener Daten ist davon abhängig, welche Informationen durch die Analysen gewonnen werden sollen. Es werden das allgemeine Vorgehen, der Einsatz der beiden Disziplinen Business Intelligence und Process Mining sowie spezielle Werkzeuge und Präsentationsformen erläutert.
Rolle
DatenvisualisiererIn
Aufschlüsseln von Pseudonymen ist untersagt
Diese Warnung wird für Umgebungen ausgesprochen, in denen pseudonymisierte Daten analysiert werden.
Das Ziel der Untersuchung der Daten ist ein Informationsgewinn. Es besteht die Gefahr, dass die Untersuchung fehlgeleitet wird und durch die Kombination von gewonnen Informationen Versuche unternommen werden, pseudonymisierte Daten aufzuschlüsseln (d. h. zum Beispiel die Klarnamen der Veranstaltenden und Teilnehmenden mit den Pseudonymen in Verbindung zu bringen). Auf Grundlage der Daten können dafür unterschiedliche Ansätze gewählt werden, die hier absichtlich nicht aufgeführt werden.
Je mehr Möglichkeiten den analysierenden Personen zur Verfügung stehen, umso vehementer sollte ihnen dieses Verbot ausgesprochen werden. Der Zugriff auf pseudonymisierte Projektmanagementdaten, in Verbindung mit dem Zugriff auf das Projektmanagementwerkzeug selbst, bietet zahlreiche Möglichkeiten, Pseudonyme aufzuschlüsseln.
Allgemeines Vorgehen#
Das Vorgehen beim Analysieren von Fakten, der Strukturen und des Verhaltens sowie die dazu einzusetzenden Analysedisziplinen, sind abhängig von den Analysefragen. Außerdem gibt es unterschiedliche Wege, die zum Ziel führen können. Aufgrund der Individualität projektbasierter Lehrveranstaltungen und der Ziele, die durch die Analysen erreicht werden sollen, kann hier ein allgemeines Vorgehen nur abstrakt beschrieben werden. Außerdem ist die Durchführung von Analysen ein Handwerk, das erlernt werden muss und hier nicht für etwaige individuelle Fälle erläutert werden kann. Zur Orientierung werden unten einige Darstellungsformen besprochen sowie die Durchführung konkreter Analysen mittels spezieller Analysedisziplinen und Werkzeugen beispielhaft beschrieben. Dadurch wird ein Einstieg geboten und es werden grundlegende Fähigkeit vermittelt, auf welche anschließend persönlich aufgebaut werden kann. Zu diesem Zweck werden außerdem Materialien verlinkt, die für den Einstieg hilfreich sein können.
Betrachtete Disziplinen sind Business Intelligence und Process Mining
Im Kontext dieses Rahmenwerks werden ausschließlich die Analysedisziplinen Business Intelligence und Process Mining (mit seiner Unterart Social Mining) betrachtet. Das bedeutet jedoch nicht, dass alle Inhalte dieses Clusters lediglich für diese beiden Disziplinen sinnvoll eingesetzt werden können. Es ist zu vermuten, dass die anderen sich zumindest teilweise gewinnbringend benutzen lassen, wenn für die Analyse andere Disziplinen ausgewählt werden, da die umgebenden Tätigkeiten sich ähneln und überschneiden sollten.
Abstrakte Prozedur:
- die vorverarbeiteten Daten müssen in die Analysewerkzeuge integriert werden bzw. diesen als Eingabe zur Verfügung gestellt werden
- je nach Analysewerkzeug könnten unterschiedliche Dateneingaben möglich sein (z. B. direkte Datenbankanbindung oder bestimmte Dateiformate)
- die Daten müssen verknüpft bzw. beschrieben werden
- je nach Werkzeug und Eingabe können die Datenmodelle (z. B. Relationen zwischen Tabellen/Dateien) definiert oder die einzelnen Attribute beschrieben werden, damit das Werkzeug versteht, wie es die Daten verknüpfen/interpretieren soll
- Analysen durchführen
- adäquate Darstellungsformen (Diagrammtypen) wählen, Daten zueinander in Beziehung setzen und filtern
Einfluss auf die Datenvorverarbeitung
Die Wahl der Analysedisziplinen sowie -werkzeuge kann die Art und Weise beeinflussen, wie die Daten bereitzustellen sind.
Disziplinen und Techniken#
Business Intelligence#
- Wikipedia - Business Intelligence
- Buch - Business Intelligence & Analytics – Grundlagen und praktische Anwendungen
- IBM - Business Intelligence
- Wirtschaftslexikon - Business Intelligence
- Wirtschaftslexikon - Online Analytical Processing (OLAP)
- Wirtschaftslexikon - Data Warehousing
- datapine - Introduction To The Basic Business Intelligence Concepts
Process Mining#
- Wikipedia - Process Mining
- Buch - Process Mining: Data Science in Action
- GI - Process Mining
- Infos und Kurse auf processmining.org
- Fluxicon - Praktische Einführung in Process Mining
Darstellungsformen#
Business Intelligence (BI)#
- Dashboards
- Diagramme
- Tabellen
Process Mining (PM)#
- Prozesse
- Netzwerke
Werkzeuge#
Auswahl
Es wird ausschließliche eine Auswahl der hier genutzten Werkzeuge präsentiert. Natürlich existieren weitere Werkzeuge, die für Business Intelligence und Process Mining genutzt werden können.
Business Intelligence#
Microsoft Power BI#
- Lernmaterialien
- Weitere Visualisierungsoptionen zum Download
Process Mining#
Disco#
- Vollständiger User Guide
- Disco Tour (als PDF)
- Demo Logs (als ZIP)
ProM#
Andere Process Mining Software benötigt?
Entsprechen weder Disco noch ProM Ihren Anforderungen, so können Sie auf der Website Process Mining Software Comparison weitere Software finden und diese miteinander vergleichen.
Konkrete Beispiele#
Untersuchung der Nutzung des Jira Issue-Trackers#
Hier wird das folgende beispielhafte Ziel aus dem Modul Analysen auswählen aufgegriffen: "Herausfinden, ob die Studierenden den Issue-Tracker (insbesondere die Status) richtig nutzen". Es soll also untersucht werden, in welchem Maße die Teilnehmenden die festgelegten Konventionen bei der Benutzung des Issue-Trackers befolgen. Zu diesem Zweck werden im Folgenden einige der Analysefragen mittels BI und PM untersucht.
Business Intelligence mit Microsoft Power BI#
Es wird dazu geraten, das das im Folgenden anzulegende Power BI Sheet Frage für Frage sukzessive zu erweitern und nicht bei jeder Frage mit einem neuen, leeren Sheet zu beginnen. Die Erläuterungen erwarten, dass die vorherigen Schritte alle durchgeführt wurden.
Außerdem setzen die Beispiele voraus, dass ein Data Warehouse mit mindestens dem Sternschema für "Jira Status" aufgebaut wurde, wie es in Modul: Daten vorverarbeiten beschrieben ist. Bei abweichendem Data Warehouse sind die unten genannten Beschreibungen zu adaptieren.
Eine Power BI Vorlage, die dabei helfen kann, einige der unten aufgeführten Fragen zu beantworten, wird unten vorgestellt und zum Download zur Verfügung gestellt.
Vorgehen:
- Stellen Sie sicher, dass der Zugriff auf das Data Warehouse möglich ist (verbinden Sie sich z. B. mit einem VPN), bevor sie mit den Untersuchungen beginnen.
- Erstellen Sie ein neues Sheet in Power BI
Wie viele Tickets wurden bereits erstellt?#
[Eindeutige Werte aufsummieren]
Vorhaben: Die Anzahl der Tickets eines Projekts zum jetzigen Zeitpunkt berechnen.
- Importieren Sie die benötigten Daten (Doku - Datenquellen in Power BI Desktop)
- Daten abrufen > Weitere... > PostgreSQL-Datenbank > Verbinden > Server[:Port] und Datenbank angeben > OK > Benutzername und Kennwort angeben > Verbinden
- Server[:Port]: Der Server und Port, unter dem das Data Warehouse erreichbar ist.
- Datenbank: Der Name der Datenbank des Data Warehouses, welche Sie auslesen möchten.
- Benutzername und Kennwort: Die Zugangsdaten, die Sie für den Data Warehouse Benutzer festgelegt haben.
- wählen Sie die benötigte Tabelle des Sternschemas aus und laden Sie diese
jira_status.dim_issue
- Daten abrufen > Weitere... > PostgreSQL-Datenbank > Verbinden > Server[:Port] und Datenbank angeben > OK > Benutzername und Kennwort angeben > Verbinden
- Fügen Sie die Visualisierung
Kartehinzu (Doku - Verwenden des Analysebereichs in Power BI Desktop) - Fügen Sie das Feld
issueder Tabellejira_status.dim_issue(enthält die eindeutige ID des Issues) zu den Datenfeldern der Visualisierung hinzu - Ändern Sie das Verhalten des Feldes von
ErsteaufAnzahl (eindeutig)(Bereich Visualisierungen > Felder > Pfeil nach unten) - Fügen Sie das Feld
projectder Tabellejira_status.dim_issue(enthält den Namen des Projektes, zu welchem das Issue gehört), zu den Filtern/Drillthrough Feldern hinzu - Wählen Sie die Projekte, nach denen Sie filtern möchten
Jetzt wird Ihnen die gesamte Anzahl der Issues angezeigt, die in den gewählten Projekten bis zum jetzigen Zeitpunkt erstellt wurden.
Wie viele Vorkommnisse der einzelnen Ticketstatus existieren in einem bestimmten Zeitraum?#
Daten konfigurieren:
Für diese Analysefrage werden außerdem die Faktentabelle selbst sowie die beiden Dimensionen benötigt, die die Zeitpunkte der Events beschreiben.
- Importieren Sie die weiteren benötigten Daten
- Daten abrufen > Weitere... > PostgreSQL-Datenbank > Verbinden > Server[:Port] und Datenbank angeben > OK > Benutzername und Kennwort angeben > Verbinden
- wählen Sie die benötigten zusätzlichen Tabellen des Sternschemas aus und laden Sie diese
jira_status.fact_status,jira_status.dim_dateundjira_status.dim_time
- Verknüpfen Sie die Tabellen im Datenmodell (unter Einbeziehung der bereits zuvor geladenen Tabelle
jira_status.dim_issue) (Doku - Erstellen und Verwalten von Beziehungen in Power BI Desktop, Doku - Modellieren von Beziehungen in Power BI Desktop)- Modell (links) > Beziehungen verwalten > Neu... > Tabellen auswählen > Spalten auswählen > Kardinalität bestimmen > Keruzfilterrichtung bestimmen > OK
- die Faktentabelle mit den jeweiligen Dimensionstabellen in Beziehung setzen (jeweiliger Foreign-Key in der Faktentabelle -> ID der zugehörige Dimensionstabelle (z. B.
issue_id->id)) - Kardinalität: n:1 (*:1)
- Kreuzfilterrichtungen:
jira_status.fact_status*<-einfach-1jira_status.dim_datejira_status.fact_status*<-einfach-1jira_status.dim_timejira_status.fact_status*<-beide->1jira_status.dim_issue
- die Faktentabelle mit den jeweiligen Dimensionstabellen in Beziehung setzen (jeweiliger Foreign-Key in der Faktentabelle -> ID der zugehörige Dimensionstabelle (z. B.
- Modell (links) > Beziehungen verwalten > Neu... > Tabellen auswählen > Spalten auswählen > Kardinalität bestimmen > Keruzfilterrichtung bestimmen > OK
Zeitstempel berechnen:
Um praktisch nach Zeiträumen filtern zu können, kann dem lokalen Datenmodell in der Faktentabelle ein Zeitstempel hinzugefügt werden.
Dazu können zunächst in den beiden Dimensionstabellen dim_date und dim_time die Attribute zu jeweils einem Datum bzw. einer Uhrzeit zusammengefasst werden.
Diese können dann in der fact_status Tabelle genutzt werden, um einen vollwertigen Zeitstempel zu berechnen.
Doku - Tutorial: Erstellen von berechneten Spalten in Power BI Desktop
- Öffnen Sie die
DatenAnsicht (links in der Leiste) (Doku - Arbeiten mit der Datenansicht in Power BI Desktop) - Wählen Sie rechts die
dim_dateTabelle aus - Klicken Sie oben auf "Neue Spalte" und tragen Sie folgendes in die neu erschienene Eingabezeile ein
full_date = DATE('jira_status dim_date'[year], 'jira_status dim_date'[month], 'jira_status dim_date'[day])
- Wiederholen Sie die obigen Schritte für die
dim_timeTabelle und tragen dort in die Eingabezeile für eine neue Spalte folgendes ein:full_time = TIME('jira_status dim_time'[hour], 'jira_status dim_time'[minute], 'jira_status dim_time'[second])
- Wiederholen Sie die Schritte ein weitere Mal für die
fact_statusTabelle und tragen dort in die Eingabezeile für eine neue Spalte folgendes ein:fact_timestamp = RELATED('jira_status dim_date'[full_date]) + RELATED('jira_status dim_time'[full_time])
Events quantitativ zueinander in Beziehung setzen:
- Fügen Sie dem Bericht ein Säulendiagramm hinzu
- rechts in der "Visualisierungen" Spalte das Säulendiagramm auswählen
- Fügen Sie der x-Achse das Attribut
fact_status.statusund der y-Achsedim_issue.issuehinzu - Ändern Sie das Verhalten für die y-Achse von
SummeaufAnzahl (eindeutig)(Pfeil nach unten auf dem eben hinzugefügten Attribut)
Zeitfilter nutzen:
Um das eben erstellte Diagramm jetzt nach einem bestimmten Zeitraum zu filtern, nutzen wir den zuvor erstellten Zeitstempel.
Doku - Hinzufügen eines Filters zu einem Bericht in Power BI
Doku - Verwenden eines Slicers und Filters für relative Zeitbereiche in Power BI
- Fügen Sie das Attribut
fact_status.fact_timestampden Filtern für diese Seite hinzu- auf der rechten Seite die Filterleiste öffnen und das Attribut unter "Filter für diese Seite" hinzufügen
- Anschließend wählen Sie den gewünschten "Filtertyp" aus und stellen den Filter ein.
- Für das Filtern nach einem längeren Zeitraum, bietet sich z. B. der Typ "Erweiterte Filterung" mit den beiden logischen Filtern "ist am oder nach" sowie "ist am oder vor" an.
Power BI Vorlagen#
Diese Power BI Vorlage wurde von Dejan Simic im Rahmen seiner Bachelorarbeit erstellt und freundlichst von ihm zur Verfügung gestellt.
Download - Power BI Template für den Jira Status Report
Sie können die Vorlage für den Jira Status Report hier herunterladen.
Wenn Sie die Vorlage öffnen, versucht Power BI die Daten zu aktualisieren und fragt in diesem Zuge nach den Verbindungsdaten für die Datenquelle, welche von Ihnen jetzt angelegt werden müssen. Doku - Datenquellen in Power BI Desktop
- Nehmen Sie zur Kenntnis, dass unten eine Adresse ausgewählt ist, welche nicht der Ihres Data Warehouses entspricht.
- Erläuterung: Das ist die Adresse, eines anderen Data Warehouses, auf welches Sie keinen Zugriff haben. Power BI erlaubt die Erstellung eines Templates nicht, ohne funktionierende Datenquelleinstellungen und somit konnte diese Adresse nicht entfernt werden.
- Klicken Sie auf
Abbrechen - und schließen Sie anschließend den "Aktualisieren"-Dialog.
- Daraufhin lädt Power BI das Template, jedoch ohne Daten.
- Klicken Sie auf
Datei > Optionen und Einstellungen > Datenquelleinstellungen - und anschließend unten links auf
Quelle ändern.... - Passen Sie den
Server(Adresse des Data Warehouses) und die zu verwendendeDatenbankdes Data Warehouses entsprechend Ihrer Umgebung an. - Nachdem Sie dies gespeichert haben, schließen Sie den Dialog und klicken anschließend im oberen Bereich in dem gelben Balken oben auf
Änderungen übernehmenund geben die Daten zur Authentifizierung ein.- Wenn Sie das Schema und die Tabellen im Data Warehouse genauso benannt haben, wie in den bereitgestellten Pentaho Spoon Transformationen angegeben (
llua_jira_status:dim_author,dim_date,dim_issue,dim_time,fact_status), sollten die Daten jetzt vollständig aktualisieren. - Wenn Sie die Namen geändert haben, dann müssen Sie jetzt die in dem Template hinterlegten Anfragen per Hand anpassen.
- Dazu klicke Sie in der linken Leiste auf
Modellansicht - und dann oben auf
Daten transformieren. Daraufhin öffnet sich der Power Query-Editor. - Links sehen Sie die Tabellen, in der Mitte die Abfrage für die Tabelle und ganz rechts
Angewendete Schritte,QuelleundNavigation.- Unter Navigation können Sie jetzt für jede Tabelle die Abfrage in der Mitte anpassen. Passen Sie das
Schemaund dasItem(Tabellenname) an (wiederholen Sie diesen Schritt für alle Tabellen).
- Unter Navigation können Sie jetzt für jede Tabelle die Abfrage in der Mitte anpassen. Passen Sie das
- Klicken Sie oben links auf
Schließend und übernehmen - und anschließend wieder in dem gelben Balken oben auf
Änderungen übernehmen.
- Dazu klicke Sie in der linken Leiste auf
- Wenn Sie das Schema und die Tabellen im Data Warehouse genauso benannt haben, wie in den bereitgestellten Pentaho Spoon Transformationen angegeben (
- Nachdem die Daten jetzt aus Ihrem Data Warehouse eingelesen wurden, können Sie in der linken Spalte wieder auf die
Berichtsansichtwechseln.
Download - weitere Power BI Templates
Bitte folgen Sie zur Anpassung der Templates an Ihre Umgebung den oben beschriebenen Schritten.
Im Folgenden werden die Dashboards und verwendeten Visualisierungen der oben bereitgestellten Vorlagen für den Jira Status Report erläutert.
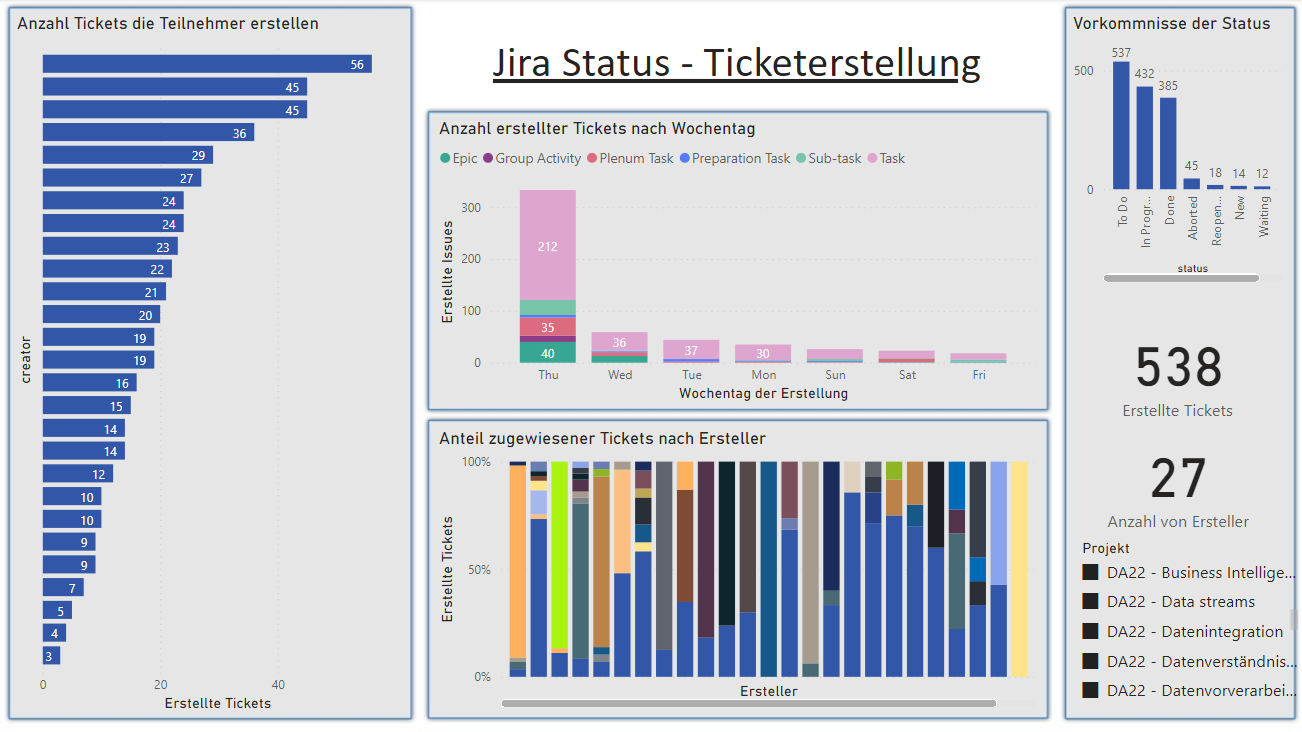
- Links
- Dargestellt ist die Anzahl der Tickets, die pro TeilenhemnerIn in einem festgelegten Zeitraum erstellt wurden.
- Damit wird die Frage "Wie verteilen sich die Ticketerstellungen über die Studierenden?" adressiert.
- Mitte oben
- Dargestellt sind die Ticketerstellungen über die Woche hinweg, aufgeteilt auf die einzelnen Wochentage. Diese wurden absteigend von links nach rechts nach der Anzahl der Ticketerstellungen sortiert.
- Damit wird die Frage "Wie verteilten sich die Ticketerstellungen über die Woche hinweg?" adressiert.
- Außerdem beinhaltet dieses Diagramm eine Erweiterung: "Wie verteilt sich die Erstellung der einzelnen Ticket-Typen über die Woche hinweg?"
- Mitte unten
- Dargestellt ist der Anteil der zugewiesenen Tickets nach erstellender Person. Dunkelblau bedeutet "nicht zugewiesen", alle anderen Farben stehen für einzelne Personen.
- Rechts (Anzahl Tickets nach Status)
- Dargestellt ist die Häufigkeit der einzelnen Statusvorkommnisse.
- Damit wird die Frage "Werden die Status richtig benutzt?" teilweise adressiert. Es gibt Aufschluss darüber, ob die Tickets überhaupt aus dem Anfangsstatus
To Dobewegt werden. Diese Frage wird unten mittels Process Mining genauer untersucht.
- Rechts (Erstellte Tickets)
- Dargestellt ist die gesamte Anzahl aller erstellten Tickets.
- Damit wird die Frage "Wie viele Tickets wurden bereits erstellt?" adressiert (siehe oben).
- Rechts (Anzahl von Ersteller)
- Dargestellt ist die Anzahl an Personen, die mindestens ein Ticket erstellt haben.
- Damit wird die Frage "Wie viele Studierende haben in einem bestimmten Zeitraum Tickets erstellt?" adressiert.
- Rechts (Projekt)
- Dargestellt ist ein interaktiver Filter, der dafür benutzt werden kann, den gesamten Bericht nach Projekten zu filtern.
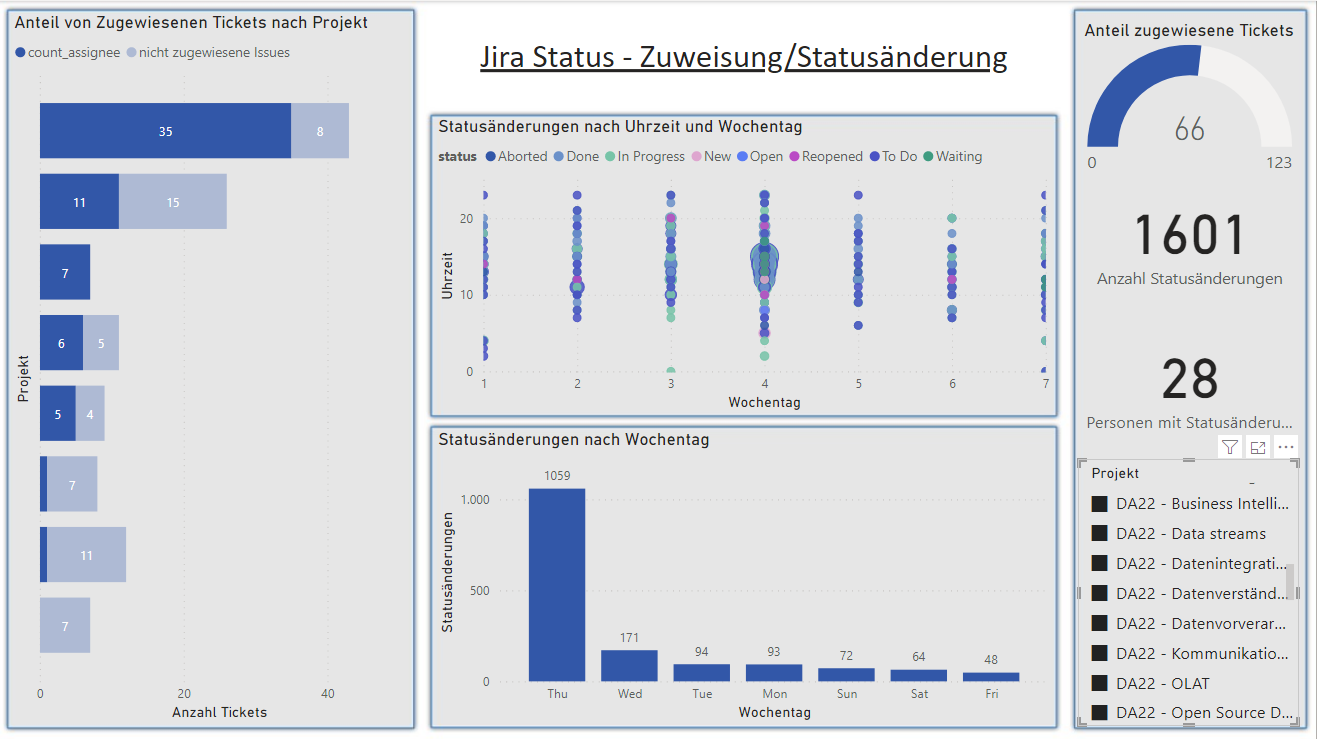
- Links
- Dargestellt ist das Verhältnis von zugewiesenen und nicht zugewiesenen Tickets nach Projekt (die hier abgebildete Lehrveranstaltung hat zu dem Zeitpunkt fünf Teilprojekte beinhaltet).
- Damit wird die Frage "Wie verhält sich der Anteil von zugewiesenen Tickets zu nicht zugewiesenen Tickets?" adressiert.
- Mitte oben
- Dargestellt sind die jeweiligen Statusänderungen nach ihrem Auftreten für Wochentage und Uhrzeiten. Je größer ein Punkt ist, desto mehr gleichartige Events sind zu einem Zeitpunkt aufgetreten. Tag 1 ist Montag.
- Damit wird die Frage "Wie verteilten sich die Statusänderungen auf die einzelnen Wochentage?" adressiert.
- Außerdem beinhaltet dieses Diagramm eine Erweiterung, indem es die Uhrzeiten berücksichtigt.
- Mitte unten
- Dargestellt ist die Summe aller Statusänderungen nach Wochentagen. Die Wochentage sind von links nach rechts absteigend nach der Anzahl der Statusänderungen sortiert.
- Damit wird ebenfalls die Frage "Wie verteilten sich die Statusänderungen der Tickets auf die einzelnen Wochentage?" adressiert. Jedoch wird hier der quantitative Aspekt hervorgehoben, wie viele Statusänderungen an den Wochentagen insgesamt zu verzeichnen sind.
- Rechts (Anteil zugewiesener Tickets)
- Dargestellt ist der Anteil und die Anzahl der zugewiesenen Tickets sowie die Anzahl aller Tickets.
- Damit wird die Frage "Wie verhält sich der Anteil von zugewiesenen Tickets zu nicht zugewiesenen Tickets?" adressiert.
- Rechts (Anzahl Statusänderungen)
- Dargestellt ist die Summe aller Statusänderungen.
- Damit wird keine Frage direkt adressiert, dient aber dazu, z. B. die Zahlen des Diagramms in der Mitte unten in Relation zu setzen.
- Rechts (Personen mit Statusänderungen)
- Dargestellt ist die Anzahl der Personen, die mindestens eine Statusänderung gemacht haben.
- Damit wird die Frage "Werden von allen Studierenden Statusänderungen vollzogen?" adressiert.
- Rechts (Projekt)
- siehe oben
Process Mining mit Disco#
Zur Untersuchung, der unten aufgeführten Fragen, werden die Daten aus dem Sternschema "Jira Status" in der Form einer flachen Tabelle als CSV-Datei verwendet (siehe Modul: Daten vorverarbeiten). Es wird erwartet, dass in der CSV-Datei mindestens die folgenden (oder äquivalente) Spalten vorhanden sind:
- status
- issueid
- author
- project (wenn nicht schon zuvor gefilter)
- timestamp
Die Bereitstellung eines beispielhaften Disco Projekts ist an dieser Stelle leider nicht sinnvoll, da ein solches immer auf den eingelesenen Daten beruht. In diesem Fall ist das jedoch kein großer Nachteil, da nur wenige einfache Schritte nötigt sind, um die unten aufgeführten Fragen zu untersuchen. Im Kontext der Fragen werden außerdem beispielhafte Darstellungen resultierender Prozesse erläutert.
Folgen die Status in der richtigen Reihenfolge aufeinander?#
[Events als Prozess darstellen]
Vorhaben: (Alle) Varianten und Cases von Statusabfolgen für die Jira Issues in einem Prozess darstellen.
Dataset Importieren:
- Starten Sie Disco
- Laden Sie Ihre eigenen Daten (CSV-Datei) (Doku - Disco User Guide: Import)
- Load your own data > Open file ...
Jetzt wird Ihnen ein Ausschnitt der Daten in Form einer Tabelle angezeigt und Sie können den einzelnen Spalten eine Bedeutung zuweisen.
- Wählen Sie die folgende Belegung der Spalten
- 'status' → Activity
- 'issueid' → Case ID
- 'author' → Resource
- 'project' → Other
- 'timestamp' → Timestamp
- stellen Sie sicher, dass z. B. Umlaute und Sonderzeichen korrekt erkannt werden
- ändern Sie ggf. das "File encoding" (unten links)
- und klicken Sie auf "Start import" (unten rechts).
Jetzt sollten Sie bereits in der "Map" einen Prozess dargestellt bekommen. Durch die oben gewählte Belegung wird die Abfolge der Status ('Activity') für jedes Issue ('issueid') dargestellt und die unterschiedlichen Variants (Abfolgen) und Cases (Issues) in einem Prozess vereinigt.
Dataset filtern:
Wenn Sie das Dataset zuvor nicht nach den zu untersuchenden Projekten gefiltert haben, können Sie dies jetzt in Disco machen (denn zurzeit zeigt der Prozess die Statusübergänge der Issues aller Projekte an, die im Dataset vorhanden sind).
- Dazu klicken Sie auf "Filter" (unten links)
- und anschließend auf "click to add filter..." (oben links).
- Dort wählen Sie den
AttributeFilter aus und wählen fürFilter byden Wert (die Spalte)projectaus. - Dann wählen Sie die Projekte aus, die Sie in Ihre Untersuchung einschließen möchten
- und klicken anschließend auf "Apply filter" (unten rechts).
Doku - Disco User Guide: Filtering
Doku - Disco User Guide: Working with Filters
Jetzt wird Ihnen ein Prozess angezeigt, der lediglich die Events beinhaltet, die zu den gefilterten Projekten gehören.
Auf der rechten Seite unter "Detail" können Sie jetzt einstellen, wie viel Prozent der Activities und Paths Sie angezeigt bekommen möchten -- also wie detailliert die Darstellung sein soll. (Doku - Disco User Guide: Map View)
Details einstellen
Activities- 0%: nur die häufigsten Aktivitäten werden angezeigt
- 100%: alle Aktivitäten werden angezeigt
Paths- 0%: nur die häufigsten Pfade werden angezeigt
- 100%: alle Pfade werden angezeigt
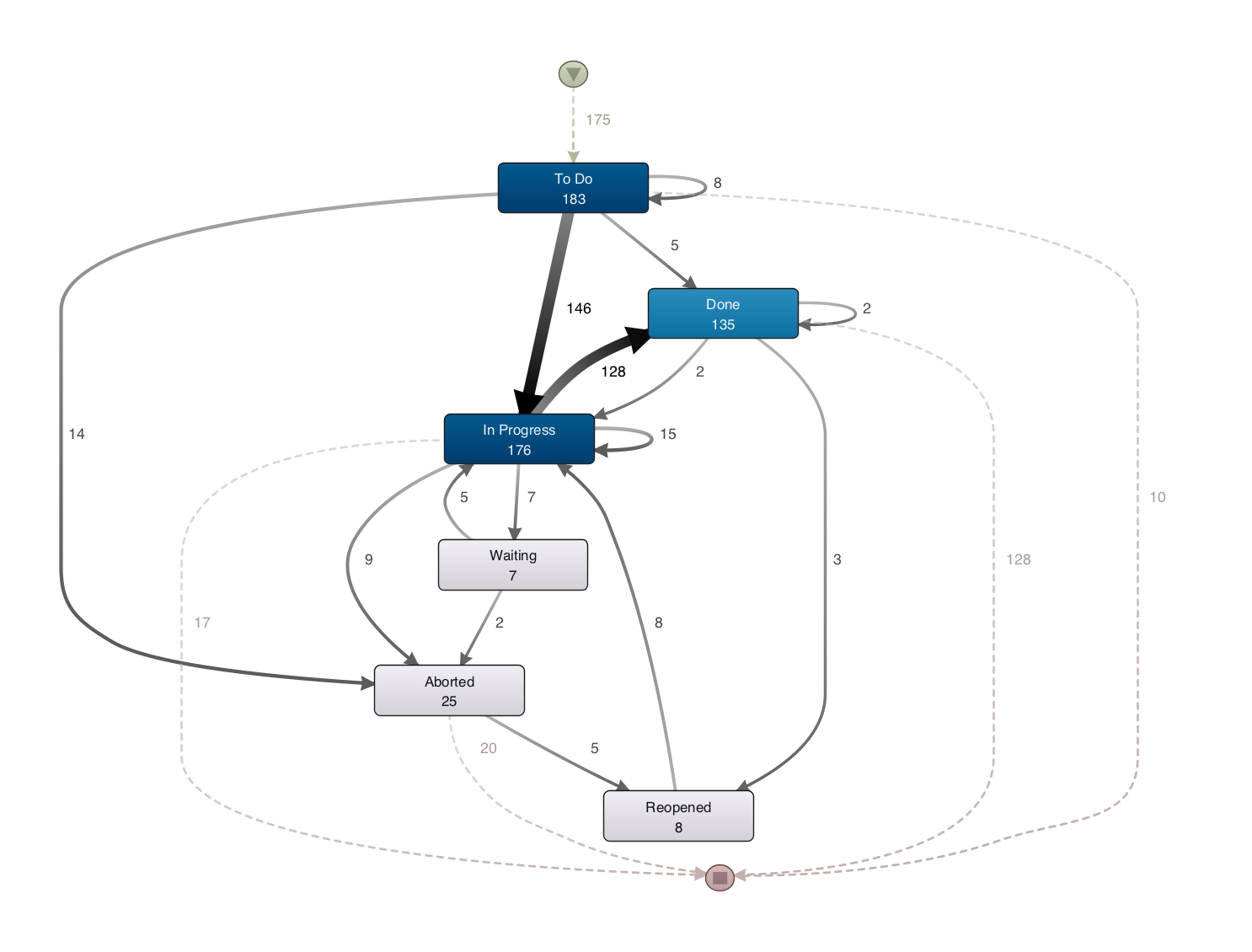
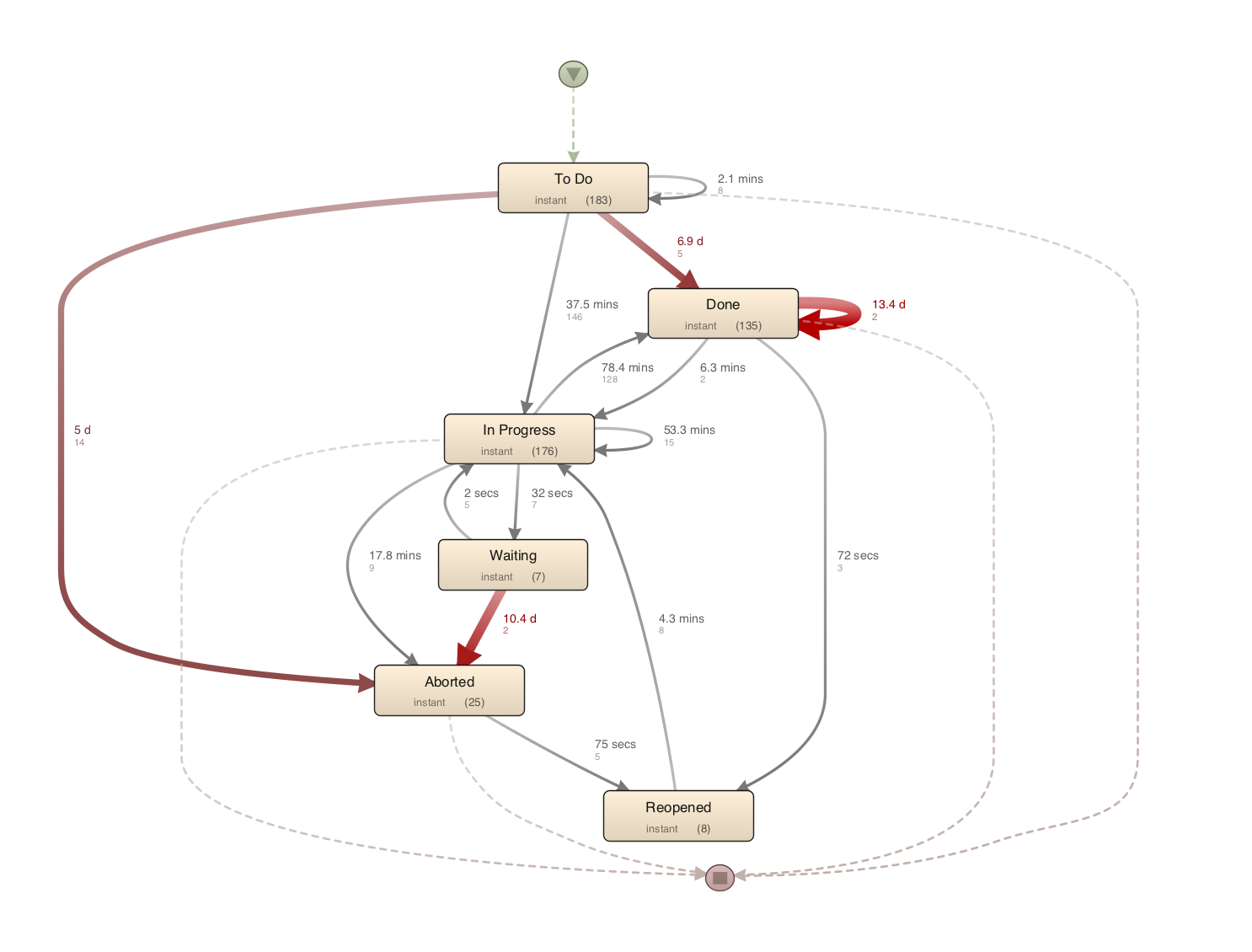
In dem oben abgebildeten beispielhaften Prozess sind die aufgezeichneten Statusübergänge von Jira Issues dargestellt. Die Zahlen beschreiben die Häufigkeit des Auftretens der Status bzw. der Übergänge.
Werden die Status richtig gepflegt (sind die Zeiten zwischen den Status realistisch)?#
[Zeitlichen Abstand zwischen Events anzeigen]
Vorhaben: Zeitabstände zwischen dem Eintreten von vollzogenen Statusänderungen anzeigen.
- Vollziehen Sie alle Schritte, die für die vorherige Fragestellung angegeben sind.
- Anschließend klicken Sie auf
Performance(rechteDetailSpalte, unten) - und wählen unter
ShowMedian durationaus.
Jetzt werden Ihnen die median Zeiten bis zur jeweils nächsten Statusänderung angezeigt.
Wir wählen hier zunächst die Median duration, um etwaigen Ausreißern entgegenzuwirken.
Je nach Ziel und Interesse können Sie sich auch andere Zeiten anzeigen lassen.
Außerdem ist es für eine bessere Einschätzung ratsam, als zweite Metrik auch noch die gesamte Anzahl des Vorkommens von Status und Statusübergängen anzeigen zu lassen (wie in der vorherigen Fragestellung).
- Dazu klicken Sie auf
Add secondary metrics(unten rechts) - und wählen
Absolute frequencyaus.
Jetzt werden Ihnen beide Metriken angezeigt. Dies hilft bei der späteren Interpretation der Analysen, um zu bewerten, aus wie vielen Vorkommnissen der zeitliche Median gebildet wird und welche Vorkommnisse ggf. genauer untersucht werden sollten.