Modul: Daten verstehen und untersuchen#

Inhalt
Um die ausgewählten Analysefragen untersuchen zu können, muss ein Verständnis über die benötigten Daten existieren. Die vorhandene Datenbasis muss erschlossen werden, um die Quellen für die benötigten Daten zu identifizieren. Außerdem sollten diese Daten auf Vollständigkeit, Risiken und Qualität hin untersucht werden. Möglicherweise müssen die Daten in ein Schema gebracht werden, sodass sie sich zu Analysezwecken nutzen lassen.
Rolle
DatenversteherIn
Definition der benötigten Daten#
Auf Grundlage der formulierten Analysefragen muss definiert werden, welche Daten prinzipiell benötigt werden, um diese zu beantworten. Zu diesem Zweck kann die Analysefrage wie folgt zerlegt werden:
- Identifizierung der Subjekte
- Identifizierung der Objekte
- Identifizierung der Tätigkeit
- Identifizierung der Einschränkungen (wie z. B. ein bestimmter Zeitraum oder ein bestimmtes Projekt)
Das Vorgehen lässt sich am besten an einem Beispiel erläutern. Zu diesem Zweck wird eine fortgeschrittene Analysefrage herangezogen, "Vollziehen alle Studierenden eines bestimmten Projekts in einem bestimmten Zeitraum Statusänderungen an Tickets?".
- Subjekte
- Studierende
- Objekte
- Tickets
- Tätigkeiten
- Statusänderung vollziehen
- Einschränkungen
- bestimmtes Projekt (es müssen beliebige Projekte ausgewählt werden können)
- bestimmter Zeitraum (es müssen beliebige Zeiträume ausgewählt werden können)
Um diese Frage zu untersuchen, müssen mindestens folgende Daten vorhanden sein:
- Die Statusänderungen von Tickets
- Wer die Statusänderung vollzogen hat (Referenz)
- Zu welchem Ticket welche Statusänderung gehört (Referenz)
- Zu welchem Projekt die Tickets gehören (Referenz)
- Wann die Statusänderung vollzogen wurde (Zeitstempel)
Erstellung eines Datenschemas#
Einfluss auf das Datenschema
Die Wahl der Analysedisziplinen sowie -werkzeuge kann die Art und Weise beeinflussen, wie die Daten bereitzustellen sind.
Bei der Erstellung eines Datenschemas ist es die Aufgabe, die benötigten Daten (die möglicherweise in unterschiedlichen Formen vorliegen und aus unterschiedlichen Quellen stammen) miteinander in Beziehung zu setzen, um sie so für Analysezwecke einfach nutzbar zu machen.
Dies wird hier an zwei Beispielen erläutert -- ein Sternschema für eine BI-Analyse und eine flache Tabelle für eine PM-Analyse.
Sternschema (BI)#
Da hier vorrangig die Änderungen von Status untersucht werden sollen, wird dieser als Fakt im Sternschema gewählt. Die anderen Daten, die dabei helfen, die Status zu filtern, werden in die Dimensionstabellen ausgelagert.
[Das folgende Sternschema wurde mit ERDPlus erstellt.]
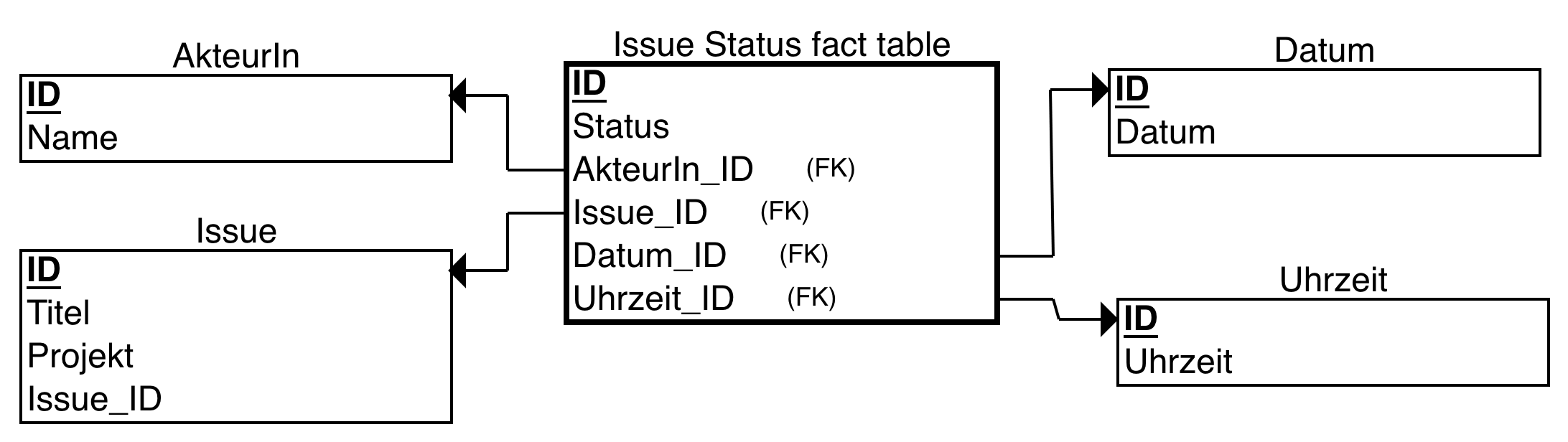
Slow Changing Dimensions (SCD) vom Typ 1 und 2
Wenn sich der Name einer AkteurIn ändert, dann ist es in den meisten Fällen in Ordnung, wenn dieser Name im Data Warehouse aktualisiert wird (-> SCD vom Typ 1).
In anderen Fällen ist es aber sinnvoll, die Historie von sich ändernden Daten beizubehalten. Zum Beispiel wenn ein Issue von einem Projekt, in ein anderes verschoben wird (-> SCD vom Typ 2). In diesem Beispiel ist die Issue Dimension eine solche SCD vom Typ 2. Damit die Daten im DWH später korrekt aktualisiert und versioniert werden können, wird ein eindeutiger Identifikator für jedes Issue benötigt. In diesem Fall wird die originale ID des Issues gewählt, welche bei der Datenvorverarbeitung ggf. pseudonymisiert werden sollte.
Flache Tabelle (PM)#
| Status | AkteurIn_Name | Issue_Titel | Issue_Projekt | Zeitstempel |
|---|---|---|---|---|
Erschließung der Datenbasis#
Je nachdem, welche Werkzeuge in der technischen Umgebung eingesetzt werden, lassen sich diese Daten in verschiedenen Formen auffinden. Dies können z. B. Datenbanken oder Log-Dateien sein.
Zum Inspizieren von Datenbanken sollte in geeignetes Werkzeug eingesetzt werden. Dazu kann z. B. Dbeaver genutzt werden. Doku - Offizieller User Guide von Dbeaver
Um das Auffinden der benötigten Daten zu vereinfachen, können sich z. B. das Datenbankschema oder eine Beschreibung der Log-Datei-Struktur eignen. Diese lassen sich möglicherweise von offiziellen Quellen beziehen oder mit speziellen Werkzeugen generieren (z. B. lässt sich mit Dbeaver in einigen Fällen die Datenbankstruktur als Diagramm darstellen).
Vollständigkeit der Datenbasis untersuchen#
Nachdem definiert wurde welche Daten prinzipiell benötigt werden und welche Datenquellen zur Verfügung stehen, die diese Daten potenziell beinhalten könnten, gilt es herauszufinden, ob für alle definierten Daten konkrete Quellen vorhanden sind. Für die oben definierten Schemata wird also definiert, aus welchen Quellen sich die Datenattribute extrahieren lassen.
Quellen finden#
Die Daten aus dem oben genannten Beispiel lassen sich alle in der Jira Datenbank finden. Im Folgenden werden anhand der flachen Tabellen die konkreten Quellen genannt:
| Status | AkteurIn_Name | Issue_Titel | Issue_Projekt | Zeitstempel |
|---|---|---|---|---|
changeitem.newstring |
changegroup.author |
jiraissue.summary |
project.pname |
changegroup.created |
Außerdem muss untersucht und beschrieben werden, mittels welcher Referenzen diese Daten miteinander in Beziehung gesetzt werden können.
Lückenfreiheit untersuchen#
Anschließend müssen diese Daten in sich auf Vollständigkeit untersucht werden. In Bezug auf das oben genannten Beispiel könnte das z. B. die folgenden Untersuchungen bedeuten:
- Sind die Statusübergänge für alle Status vorhanden oder werden nur spezielle Statusübergänge oder die spezieller Ticket-Typen aufgezeichnet?
- Sind die Statusübergänge für alle (zu untersuchenden) Projekte vorhanden oder werden nur die einiger Projekte aufgezeichnet?
- Sind die Statusübergänge für alle (zu untersuchenden) Zeiträume vorhanden oder werden die Statusübergänge nur für spezielle Zeiträume aufgezeichnet?
Risiken der Datenbasis untersuchen#
Es ist jetzt bekannt, welche Daten zur Untersuchung der Analysefrage benötigt werden, wo diese Daten zu finden sind und was sie beinhalten. Im nächsten Schritt sollten diese Daten hinsichtlich verschiedener Risiken untersucht werden. Auf der einen Seite steht die Wahrung des Datenschutzes und der Persönlichkeitsrechte. Auf der anderen Seite stehen die Risiken, die von fehlerhaften Daten ausgehen können.
Datenschutz und Persönlichkeitsrechte#
Im Folgenden wird wieder davon ausgegangen, dass mit den zu untersuchenden Personen vereinbart wurde, dass nur pseudonymisierte Daten untersucht und sonstige Daten, die die UrherberInnen preisgeben, nicht verwendet werden dürfen.
Um die vorliegenden Daten hinsichtlich dieser Kriterien zu untersuchen, könnten u. a. die folgenden Fragen beantwortet werden:
- Enthalten die Spalten in den Tabellen direkt persönliche Daten, wie z. B. Namen, E-Mail oder IP-Adressen?
- Existieren Spalten, die indirekt persönliche Informationen preisgeben könnten, wie z. B. geschriebene Texte oder IDs, die in dem Werkzeug, aus dem diese Stammen (in diesem Fall Jira), gefunden werden könnten?
- Lassen sich aus der Kombination von Spalten Informationen gewinnen, die zur Identifizierung von z. B. Personen führen könnten?
Die Behandlung identifizierter Risiken ist individuell und vielseitig. Es muss jeweils abgewägt werden, wie hoch das Risiko ist und ob die Daten für die Analyse benötigt werden. In einigen Fällen lassen sich die Wahrung des Datenschutzes und der Persönlichkeitsrechte nicht mit der Durchführung der Analyse in Einklang bringen. Andere Fälle lassen sich jedoch gut behandeln, wie im Folgenden an dem oben genannten Beispiel beschrieben wird:
Das Risiko einiger Datenfelder variiert. Ein Faktor ist z. B., ob die Personen, die an der Datenanalyse beteiligt sind, selbst in den Daten auftauchen oder nicht. Ein zweiter Faktor wäre z. B., ob die Personen, die an der Datenanalyse beteiligt sind, Zugriff auf die Werkzeuge haben, aus denen diese Daten stammen (in diesem Falle, Zugriff auf die zu untersuchenden Jira Projekte). Zur Veranschaulichung der Risikoanalysen wird hier davon ausgegangen, dass die DatenanalytikerIn sowohl in den Daten auftaucht als auch Zugriff auf die Projekte hat (eine risikoreiche Kombination).
| Quelle | Risiko | Daten benötigt | Mögliche Behandlungen | Gewählte Behandlung | Begründung |
|---|---|---|---|---|---|
Status: changeitem.newstring |
niedrig | ja | keine | - | siehe unten (1) |
AkteurIn_Name: changegroup.author |
hoch | ja | Pseudonymisieren, Anonymisieren | Pseudonymisieren | siehe unten (2) |
Issue_Titel: jiraissue.summary |
hoch | nein | nicht verwenden | nicht verwenden | siehe unten (3) |
Issue_Projekt:project.pname |
niedirig | ja | keine | - | siehe unten (4) |
Issue_ID:jiraissue.id |
hoch | ja | Pseudonymisieren | Pseudonymisieren | siehe unten (5) |
Zeitstempel: changegroup.created |
hoch | ja | Verfälschen (Binning, addieren/subtrahieren fester Werte) | Binning | siehe unten (6) |
| Issue_Titel + AkteurIn_Name | hoch | siehe oben | siehe oben | siehe oben | siehe unten (7) |
| Zeitstempel + AkteurIn_Name | hoch | ja | siehe oben | siehe oben | siehe unten (8) |
Begründungen:
(1): Der Status ist der Fakt, der untersucht werden soll. Ein Risiko würde bestehen, wenn z. B. nur eine Person dazu berechtigt ist, einen bestimmten Status zu setzen oder ein Status bisher nur von einer Person benutzt wurde.
(2): Es soll herausgefunden werden, ob alle Studierenden Statusänderungen vollziehen. Dies kann über die Gesamtzahl ermittelt werden. Anonymisierung würde das Zählen der AkteurInnen nicht möglich machen.
(3): Der Titel eines Issues ist Freitext. Freitext hat immer ein hohes Risiko, auch wenn kein Zugriff auf das Projekt besteht, denn der Titel könnte z. B. "Sprich einen Termin mit Herrn Schmitz ab" lauten. Außerdem wird der Titel für die Analyse nicht benötigt.
(4): -
(5): Die ID des Issues dient als eindeutiger Identifikator und wird zur Behandlung der SCD vom Typ 2 benötigt. Durch die ID ließen sich jedoch die Pseudonyme der AktuerInnen einfach herausfinden. Es muss nur die Eindeutigkeit bewahrt werden. Eine über die Zeit einheitliche Pseudonymisierung ist dafür ein guter Ansatz.
(6): Durch einen sekundengenauen Zeitstempel, lassen sich eigene Aktivitäten schnell identifizieren oder mit den Daten in dem Projekt vergleichen. Die Analysefrage zielt zwar auf die Untersuchung bestimmter Zeiträume ab, diese müssen aber nicht sekundengenau angegeben werden. Hier könnten z. B. die Sekunden und Minuten weggelassen werden (Binning).
(7): Siehe [3]. Außerdem lassen sich Freitexte, die man selbst formuliert hat, oft wiedererkennen. In Kombination mit dem pseudonymisierten Namen ließe sich so sein eigenes Pseudonym identifizieren.
(8): Durch diese Kombination lässt sich leicht das eigene Pseudonym oder das anderer herausfinden, wenn man weiß, wer wann was getan hat. Weglassen von Sekunden und Minuten kann hier ebenfalls helfen.
Fehlerhafte Daten#
Das Ziel dieses Abschnitts ist es, ein Bewusstsein dafür zu erzeugen, dass die Untersuchung fehlerhafter Daten ein Risiko darstellen kann. Die Untersuchung der Datenbasis auf Fehler steht im Zentrum des nächsten Abschnitts.
Fehlerhafte Daten können zu fehlerhaften Analysen und somit zu falschen Interpretationen und Anpassungsvorschlägen führen (garbage-in -> garbage-out). Aus diesem Grund ist es wichtig, die Daten auf potenzielle Fehler hin zu untersuchen (siehe nächster Abschnitt).
Siehe auch die Warnung "Achtung vor fehlerhaften Analysen" im Modul: Analysen bewerten und interpretieren.
Qualität der Datenbasis untersuchen#
Während sich wenige Vorkommnisse von qualitativen Mängeln in der Datenbasis bereinigen/korrigieren lassen, ist eine Datenbasis, die allgemein eine schlechte Qualität aufweist, nicht für Datenanalysen zu verwenden. In solchen Fällen muss die Datenaufzeichnung grundlegend verbessert werden.
Die ausgewählten Daten können zur Einschätzung der Qualität z. B. auf die folgenden Mängel hin untersucht werden:
- Fehlende Werte
- Sind z. B. die Spalten einzelner Zeilen leer?
- Ausreißer
- Weichen die Werte einzelner Zeilen unerwartet stark von den Werten der restlichen Zeilen ab?
- Grenzwerte überschritten
- Überschreiten die Werte einzelner Zeilen Grenzwerte?
- Beschreibt ein Zeitstempel z. B. einen Zeitpunkt, der zu weit in der Vergangenheit oder sogar in der Zukunft liegt?
- Überschreiten die Werte einzelner Zeilen Grenzwerte?
- Duplikate
- Kommen einzelne Datensätze/Zeilen (bis auf z. B. ihre ID) mehr als einmal vor?
- Unterschiedliche Formate
- Sind z. B. die Datums- und Uhrzeitangaben in den gleichen Formaten/in der gleichen Zeitzone oder müssen diese aneinander angepasst werden?
An dieser Stelle auf alle möglichen Mängel und die Facetten der Datenqualitätssicherung einzugehen, würde den Umfang übersteigen. Bei weiterem Interesse wird der Artikel Datenqualität messen: Mit 11 Kriterien Datenqualität quantifizieren empfohlen.