Modul: Daten vorverarbeiten und sammeln#

Inhalt
Um die Daten effizient für Analysen zur Verfügung zu stellen, sie in ein einheitliches Format zu bringen und ggf. zuvor identifizierte Risiken sowie Fehler zu behandeln, werden die Daten vorverarbeitet und gesammelt. Es wird ein allgemeines Vorgehen beschrieben und wie dieses Vorgehen konkret mit der exemplarischen LLUA umgesetzt werden kann. Dazu wird auf alle Schritte von der Extraktion der Daten bis zur Bereitstellung der Sammlung eingegangen.
Rolle
DatenintegratorIn
Einfluss auf die Datenvorverarbeitung
Die Wahl der Analysedisziplinen sowie -werkzeuge kann die Art und Weise beeinflussen, wie die Daten bereitzustellen sind.
Allgemeines Vorgehen#
Im Prinzip besteht die Datenvorverarbeitung und -sammlung aus den folgenden Schritten:
- Daten extrahieren
- Daten transformieren
- Daten laden
Diese Abfolge wird als ETL-Prozess bezeichnet. Dem gegenüber steht der ELT-Prozess in welchem -- wie der Name vermuten lässt -- die Schritte transformieren und laden vertauscht sind. Die Unterschiede sowie vor und Nachteil von ETL und ELT können z. B. hier nachgelesen werden. In diesem Modul wird die Datenvorverarbeitung und -sammlung anhand des ETL-Prozesses beschrieben.
Am Anfang stehen eine oder mehrere Quellen, aus denen die Daten extrahiert werden sollen. Am Ende steht eine Datensammlung, in der alle für die Analyse benötigten Daten integriert sind.
Quellen#
Auf die Quellen der Daten wurde bereits im Modul: Daten verstehen und untersuchen eingegangen.
Senke (Datensammlung)#
In dem hier vorliegenden Beispiel wird für BI als Senke ein Data Warehouse (DWH) eingesetzt. Wie dieses DWH in die LLUA integriert ist, wird hier beschrieben. Die Inbetriebnahme dieses DWH wird hier erläutert.
Für PM wird eine CSV-Datei vorbereitet, die automatisiert zum Download bereitgestellt wird.
Werkzeuge#
Zur Vorverarbeitung der Daten können unterschiedliche Ansätze verfolgt werden. Die Spanne reicht von der Nutzung selbst entwickelter Skripte/Programme, über Tabellenverarbeitungsprogramme, hin zu für die Datenintegration spezialisierte Programme - oder eine Kombination der zuvor genannten. Welcher Ansatz verfolgt werden sollte, hängt sowohl von den Quellen als auch der/den Senke(n) ab, sowie von den vorhandenen Vorkenntnissen.
Im Kontext der exemplarischen LLUA hat sich eine Kombination aus selbst entwickelten Skripten und spezialisierten Datenintegrationsprogrammen bewährt. Dabei wird der Hauptteil der Arbeit von letzteren übernommen. Die Skripte dienen vorrangig dazu, erzeugte Daten zu verschieben, um diese zum Download bereitzustellen.
In der vorgestellten LLUA wird das Datenintegrationsprogramm Pentaho Spoon in der Version 9.1 eingesetzt. Für dieses werden unten einige Prozeduren (genannt Transformationen) bereitgestellt und außerdem werden an diesem einige der Prinzipien der Datenvorverarbeitung illustriert.
Die offizielle Dokumentation für die Datenverarbeitung mit Pentaho Spoon ist hier zu finden.
Pentaho Spoon Step Reference
Eine Übersicht der Dokumentation aller Steps in Spoon ist hier zu finden.
Download und Anpassung von Spoon Transformationen#
Wenig Erfahrung mit Pentaho Spoon?
Wenn Sie gar keine oder wenig Erfahrung mit Pentaho Spoon haben, lesen Sie am besten erstmal weiter, bevor Sie versuchen, die zur Verfügung gestellten Transformationen (im Detail) zu verstehen.
(Optional) Wenn Sie möchten, können Sie diese zum Nachvollziehen der Erläuterungen in den folgenden Abschnitten heranziehen.
Klardaten
Die hier zur Verfügung gestellten Transformationen beinhalten weder eine Anonymisierung bzw. Pseudonymisierung noch eine Bereinigung der Daten. Dies müssen Sie selbst nach Ihren eigenen Bedürfnissen ergänzen.
Download - Pentaho Spoon Transformationen und Jobs
Es wird empfohlen, die Datenbank Schemata und die Tabellen der Stern-Schemata so zu benennen, wie diese in den Transformationen definiert sind. Das erleichtert Ihnen später die Nutzung der hier zur Verfügung gestellten Power BI Templates.
- Transformationen
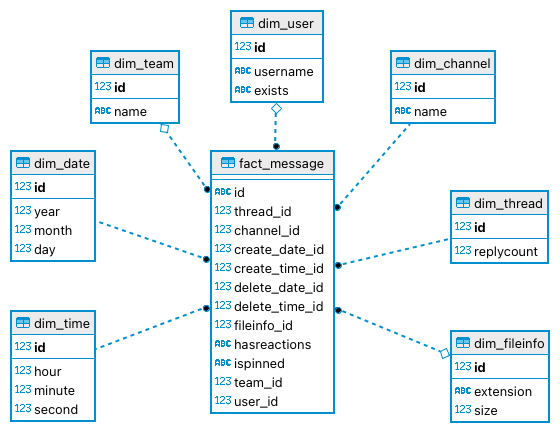
- Mattermost Message
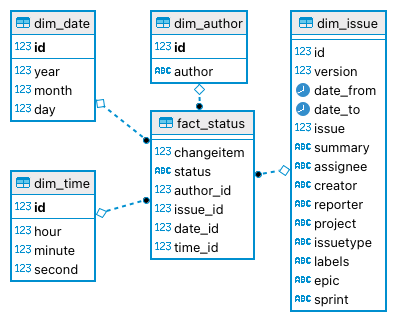
- Jira Status
- Data Warehouse Star Schema
- Transformation
- Helper-Transformation
- Wird benötigt und ist in den gleichen Ordner wie die "Transformation" zu legen.
- Diese Helper-Transformation wird von der eigentlichen Transformation aufgerufen. Sie stellt die Dimension für das Jira Issue zusammen. Die Extraktion dieses Teils sorgt für eine übersichtlichere "Haupt"-Transformation.
- Bitte nehmen Sie die Anmerkung in der Transformation auf der linken Seite in der Mitte zur Kenntnis (!!!...!!!).
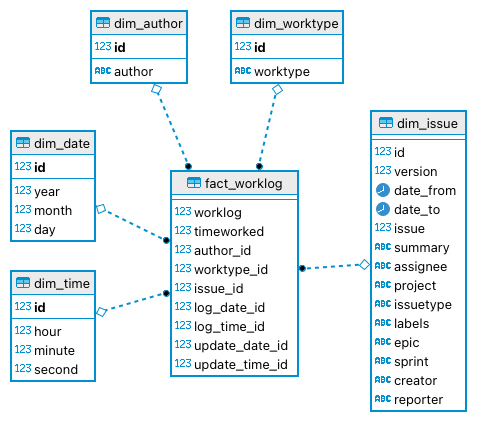
- Jira Worklog
- Data Warehouse Star Schema
- Transformation
- Diese Transformation erwartet, dass Sie das WorklogPRO Addon für Jira installiert haben und nutzen.
- Bitte nehmen Sie die Anmerkung in der Transformation auf der linken Seite oben zur Kenntnis (!!!...!!!). Wenn Sie kein Custom Attribute in WorklogPRO angelegt haben, nehmen Sie bitte die beschriebenen Änderungen vor. Oder legen Sie ein sinnvolles Custom Attribute an. "worktype", wie hier unter Konfiguration des WorklogPRO Addons beschrieben, ist für die Auswertungen sehr hilfreich.
- Helper-Transformation (siehe oben)
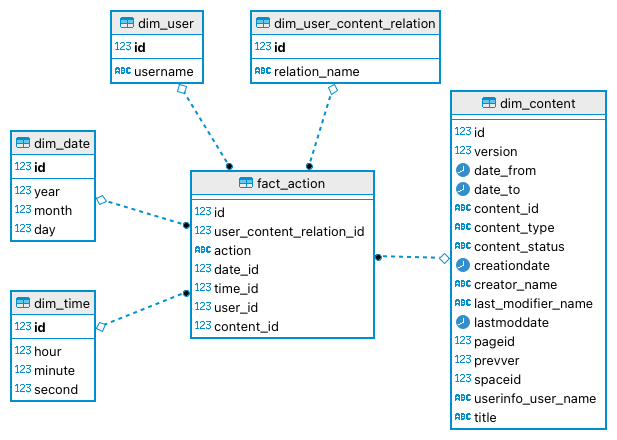
- Confluence Access Log
- Data Warehouse Star Schema
- Transformation
- Diese Transformation erwartet, dass Sie das Access Log for Confluence Addon für Confluence installiert haben und nutzen.
- Jobs
- Job: Führt alle zuvor aufgeführten Transformationen in einem Job aus.
- Sie müssen den Job in das gleiche Verzeichnis wie die Transformationen legen oder die Pfade in den Transformation-Steps anpassen. Wenn Sie den Job und somit die Transformationen auf dem Server ausführen möchten, benutzen Sie am besten vollständige Pfade zu den Transformationen.
- Wenn Sie die Dateinamen der Transformationen angepasst haben, müssen Sie diese ebenfalls anpassen.
- Job: Führt alle zuvor aufgeführten Transformationen in einem Job aus.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Wenn Sie die zur Verfügung gestellten Pentaho Spoon Transformationen nutzen möchten, müssen Sie jeweils die Verbindung zur Quelldatenbank sowie zum Data Warehouse konfigurieren. Doku - Open the Database Connection dialog box from PDI
- Dazu öffnen Sie eine Transformation in Spoon
- und klappen dann auf der linken Seite unter
View > Transformations > [name_der_transformation]dieDatabase connectionsauf. - Anschließend klicken Sie mit rechter Maustaste auf die jeweilige Verbindung und passen diese an.
- Beachten Sie dabei, ob Sie die Quelldatenbank auf einen Host-Port gebunden oder diese zusammen mit dem Pentaho Server Container in einem Docker Netzwerk haben.
- Nachdem Sie alle Daten eingegeben haben, testen Sie die Verbindung, indem Sie unten auf den
TestButton klicken.
Daten extrahieren#
Im ersten Schritt des Datenvorverarbeitungsprozesses gilt es, die Daten aus den einzelnen Quellen zu extrahieren. Spoon bietet dazu unterschiedliche Steps an. Mit diesen können z. B. Daten aus Textdateien (CSV, JSON, XML, ...), Datenbanktabellen und von online Services, wie Google Analytics und AWS eingelesen werden.
In dem vorliegenden Beispiel werden die Daten einer Datenbanktabelle mit Hilfe des Table Input Steps ausgelesen:
Voraussetzung
Die Datenbank ist über das Netzwerk/Internet erreichbar. Siehe hier.
- Öffnen Sie eine neue Transformation in Spoon (File > New > Transformation).
- Wechseln Sie oben links in Spoon von dem View auf den Design Tab.
- Öffnen Sie den Ordner Input
- und ziehen sie den Step
Table Inputauf die rechte Seite (Canvas der Transformation). - Öffnen Sie den Step mit einem Doppelklick und fügen Sie eine neue Datenbankverbindung zu Ihrer Quell-Datenbank hinzu (New... oder Wizard...).
- Klicken Sie auf Get SQL select statement...
- und wählen Sie die Tabelle aus, aus der Sie die Daten extrahieren wollen.
- Bestätigen Sie eine Frage wie "Do you want to include the field-names in the SQL?" mit Yes
- und löschen Sie anschließend alle Felder, die Sie nicht benötigen (festgelegt in Modul: Daten verstehen und untersuchen).
- Überprüfe Sie mittels eines Klicks auf Preview, ob die Verbindung funktioniert.
- Schließen Sie die Konfiguration des Steps anschließend mit OK ab.
Dieses Vorgehen führen Sie jetzt für alle benötigen Datenbanktabellen durch.
Daten transformieren#
Das Vorgehen für das Daten transformieren lässt sich nur prinzipiell beschreiben. Dieser Vorgang wird hier in zwei Bereiche geteilt: Daten verknüpfen und Daten bereinigen.
Daten verknüpfen#
Beim Daten verknüpfen ist es das Ziel, aus den einzelnen Quellen, eine einheitlich flache Tabelle zu kreieren. Im Idealfall kann die Verknüpfung durch IDs vorgenommen werden (wie es auch in relationalen Datenbanken der Fall ist). Für diesen Vorgang werden vorrangig die folgenden drei Steps in Spoon verwendet:
Oft bietet es sich an, mit der Tabelle zu beginnen, die den Fakt enthält (siehe Sternschema) und diesen Schritt für Schritt, um weitere Informationen anzureichern.
Bevor zwei Data Streams mit einem Merge join zusammengeführt werden, müssen diese jeweils nach der Spalte (ggf. ID) sortiert werden, über die der Merge vollzogen werden soll (der Merge join geht jede Zeile nur einmal durch).
Neben der Selektion der beiden Data Streams (bzw. Input Steps) und der Auswahl der jeweiligen Felder (Key field) über die der Merge vollzogen werden soll, ist dem Join Type eine besondere Aufmerksamkeit zu schenken.
Wie die einzelnen Typen die Data Streams behandeln, ist in der oben verlinkten Doku zum Merge join nachzulesen.
Welcher Typ eingesetzt werden sollte, hängt davon ab, wie die Daten nach dem Merge geartet sein sollen.
Merge join und Fakten
Beim Merge join sollte darauf geachtet werden, dass aus dem Data Stream, der den Fakt beinhaltet, keine Zeilen verloren gehen.
Beispiel: Ist dieser Data Stream, der den Fakt beinhaltet, als First Step selektiert, sollte in den meisten Fällen der Join Type LEFT OUTER gewählt werden.
Sollten sich in den zwei zusammengeführten Data Streams Felder befinden, die die gleiche Bezeichnung haben, so wird eines dieser Felder mit einem Suffix versehen (z. B. _1).
Diese Felder sollten umbenannt werden, damit im späteren Verlauf der Transformation deutlich ist, woher sie kommen.
Die Umbenennung kann mit dem Step Select values unter (Select & Alter) erfolgen.
Mit diesem Step können auch nicht mehr benötigte Felder entfernt werden (Remove).
Führen Sie diesen Vorgang so lange durch, bis alle Ihre Daten wie gewünscht miteinander verknüpft sind.
Daten bereinigen#
Im zweiten Bereich der Datentransformation werden die Daten bereinigt. Dazu zählen u. a. die Tätigkeiten:
- Pseudonymisierung/Anonymisierung
- Fehlerkorrektur
- Vereinheitlichung von abweichenden Formaten
- hinzufügen fehlender Werte
Die zu bereinigten Daten wurden zuvor in dem Modul: Daten verstehen und untersuchen identifiziert (insb. in den Schritten Risiken der Datenbasis untersuchen und Qualität der Datenbasis untersuchen).
Beispiel: Pseudonymisierung#
Prinzipiell kann eine Pseudonymisierung von Benutzernamen z. B. wie folgt realisiert werden:
- Zunächst wird dem Data Stream mit
Add constantsein beliebiger Wert hinzugefügt, dieser wird anschließend als Salt für eine Hash-Funktion verwendet. - Anschließend wird mit
Add checksumaus der Kombination des Benutzernamens und des eben erzeugten Salts eine Checksum berechnet. Dabei wird gleichzeitig ein Name für das Feld vergeben (z. B. name_pseudo), das die Pseudonyme beinhalten soll. - Im nächsten Step werden mit
Select valuesdie Felder, die den originalen Benutzernamen und den Salt beinhalten entfernt.
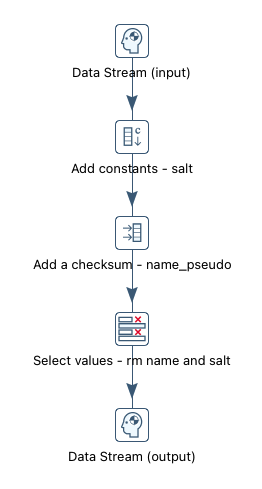
Schwachstelle dieser Pseudonymisierung
Dies ist ein sehr einfacher und zweckmäßiger Ansatz, der jedoch auch eine Schwachstelle beinhaltet.
Bevor die originalen Benutzernamen mit dem Select values Step entfernt werden, befinden sich sowohl die generierten Pseudonyme als auch die originalen Benutzernamen im Data Stream. Die DatenintegratorIn könnte diese beim Ausführen der Transformation auslesen oder sogar zwischenspeichern.
Beispiel: Formate vereinheitlichen#
Spoon bietet viele Steps an, die dabei helfen können, die Vereinheitlichung von Formaten gleicher Informationen zu vollziehen.
Im Folgenden wird dieses anhand unterschiedlicher Zeitstempel prinzipiell beschrieben.
Wir nehmen also an, dass z. B. in dem Feld created unterschiedliche Formate vorkommen (z. B. 1970-01-02-03-04-05 und 1970-01-02T03:04:05).
Mit dem Step Calculator können aus unterschiedlichen Zeitstempelformaten die einzelnen Komponenten (year, month, day, hour, minute) ausgelesen und auf diese aufgeteilt werden.
In anderen Fällen könnte sich dazu z. B. der Step Split fields als hilfreich erweisen.
- Zunächst wird dem Data Stream der Step
Calculatorhinzugefügt. - Für jede zu extrahierende Komponente der Zeitstempel wird im
Calculatorein neues Feld hinzugefügt, - als Field A wird in unserem Beispiel
createdgewählt - und die Calculation entsprechend ausgewählt (Year of date A, Month of Data A usw.).
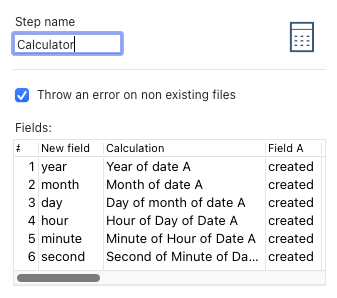
Dadurch wird der Data Stream um sechs weitere Felder angereichert (wenn alle Komponenten genutzt werden sollen), die anschließend entweder so bestehen bleiben oder mit einem oder mehreren Concat fields Steps in einem beliebigen Format wieder zusammengesetzt werden können.
Daten laden#
Unter dem Laden von Daten versteht man, die Senke(n) zu befüllen. Wie oben angegeben, sind diese in diesem Beispiel ein DWH (für BI) und CSV-Dateien (für PM). Im DWH werden die Daten in der Form des festgelegten Sternschemas abgelegt. Eine CSV-Datei steht für sich und beinhaltet eine flache Tabelle.
Beides kann ebenfalls mit Spoon in der gleichen Transformation erfolgen, die wir in den vorherigen Schritten bereits begonnen haben.
Business Intelligence (DWH)#
Voraussetzung
Ein aufgesetztes und für die DatenintegratorIn erreichbares Data Warehouse. (Siehe hier)
Um das Data Warehouse mit den vorverarbeiteten Daten zu befüllen, müssen prinzipiell die folgenden Tätigkeiten erfolgen:
- Aufteilen des Data Streams in die Faktentabelle und die Dimensionstabellen
- Anlegen des Datenbankschemas (Sternschema) im DWH
- Einfügen/Updaten der Daten ins/im DWH
In Spoon können dafür die folgenden Steps eingesetzt werden:
Combination lookup/update- Zum Befüllen der Tabellen für Slow Changing Dimensions (SCD) vom Typ 1Dimension lookup/update- Zum Befüllen der Tabellen für SCD vom Typ 2Select values- Zum Löschen und Umbenennen von FeldernInsert / Update- Zum Befüllen der Faktentabelle
Die Steps Combination lookup/update, Dimension lookup/update und Insert / Update unterstützen jeweils für sich die drei oben aufgeführten Tätigkeiten.
Lediglich das Anlegen des Datenbankschemas wird nicht vollständig unterstützt (siehe unten).
Anlegen des Datenbankschemas#
Das gewählte Datenbankschema für die einzelnen Tabellen kann z. B. "per Hand" mit einer Datenbankadministrationssoftware wie Dbeaver oder mit Unterstützung der oben genannten Steps erzeugt werden.
Das Schema selbst muss jedoch manuell angelegt werden.
- Öffnen Sie Dbeaver und verbinden Sie sich mit Ihrem Data Warehouse.
- Navigieren Sie links in die Datenbank, bis Sie den Ordner
Schemassehen. - Klicken Sie mit der rechten Maustaste auf diesen Ordner und wählen Sie
Create New Schema.
Im Folgenden wird die Erstellung der Tabellen mit der Unterstützung des Spoon Steps Combination lookup/update am Beispiel der Dimension AkteurIn (SCD vom Typ 1) beschrieben.
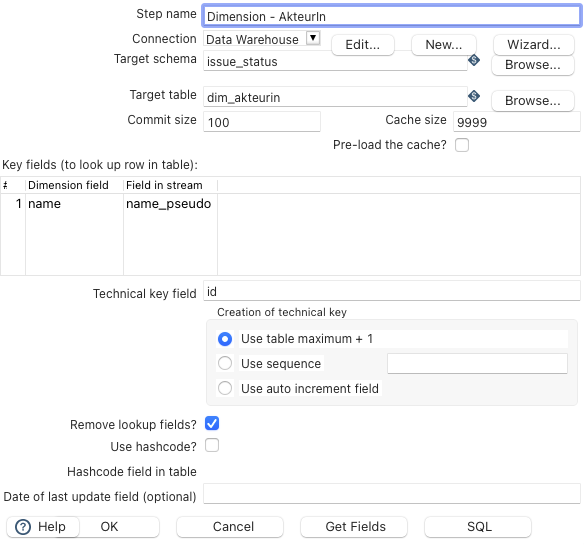
Dieser Step könnte wie oben abgebildet konfiguriert werden. Da diese Dimension nur zwei Felder beinhaltet soll, wovon eines die ID ist (siehe Technical key field), muss dem Bereich Key fields lediglich eine Zeile hinzugefügt werden. Diese beschreibt, wie das Feld im DWH heißen soll und wie es im aktuellen Data Stream heißt.
Nachdem dieser Step entsprechend konfiguriert wurde, kann durch einen Klick auf den Button SQL unten rechts SQL-Code erzeugt und anschließend ausgeführt werden.
Dadurch wird diese entsprechende Tabelle erzeugt.
Das funktioniert ebenfalls mit den Dimension lookup/update und Insert / Update Steps.
Durch den Haken bei Remove lookup field? werden außerdem alle Felder des Data Streams, die in Key fields beschrieben sind, nach diesem Step aus dem Data Stream entfernt. Der Data Stream wird dadurch also automatisch aufgeräumt.
Dieses Vorgehen wird für alle SCD vom Typ 1 durchgeführt. Das Vorgehen für SCD vom Typ 2 wird im nächsten Abschnitt beispielhaft besprochen.
Leider werden durch dieses Vorgehen keine Foreign Keys und Constraints zwischen den Datenbanktabellen definiert. Dies kann manuell nachgeholt werden (z. B. mit Dbeaver).
Befüllen des Datenbankschemas#
Die zuvor erstellen Steps Combination lookup/update für die SCD vom Typ 1 decken bereits das Befüllen der zugehörigen Datenbanktabellen ab.
Hier wird beschrieben, wie der Data Stream aufgeräumt werden kann und was nötigt ist, um die Faktentabelle mit sinnvollen Daten zu befüllen.
Zusätzlich wird auf auf die SCD vom Typ 2 eingegangen.
Nachdem ein Combination lookup/update oder Dimension lookup/update Step durchgelaufen ist, wird dem Data Stream ein neues Feld (z. B. id_1) hinzugefügt, welches die IDs auf die eben erzeugten Zeilen in der Dimension beinhaltet.
Dieses Feld wird später als z. B. issue_id in die Faktentabelle geschrieben.
Dazu sollte das Feld mit dem Step Select values entsprechend umbenannt werden, um den Überblick im Data Stream zu bewahren und später sinnvolle und richtige Daten (Referenzen) in die Faktentabelle zu schreiben.
Wenn sich der Name einer Person ändert, dann ist es in den meisten Fällen in Ordnung, wenn dieser Name im Data Warehouse aktualisiert wird. In anderen Fällen ist es aber sinnvoll, die Historie von sich ändernden Daten beizubehalten. Zum Beispiel wenn ein Issue von einem Projekt, in ein anderes verschoben wird (-> SCD vom Typ 2).
Um SCD vom Typ 2 zu behandeln, kann in Spoon der Dimension lookup/update eingesetzt werden.
Dies wird im Folgenden an dem Beispiel der Issue Dimension (dim_issue) erläutert.
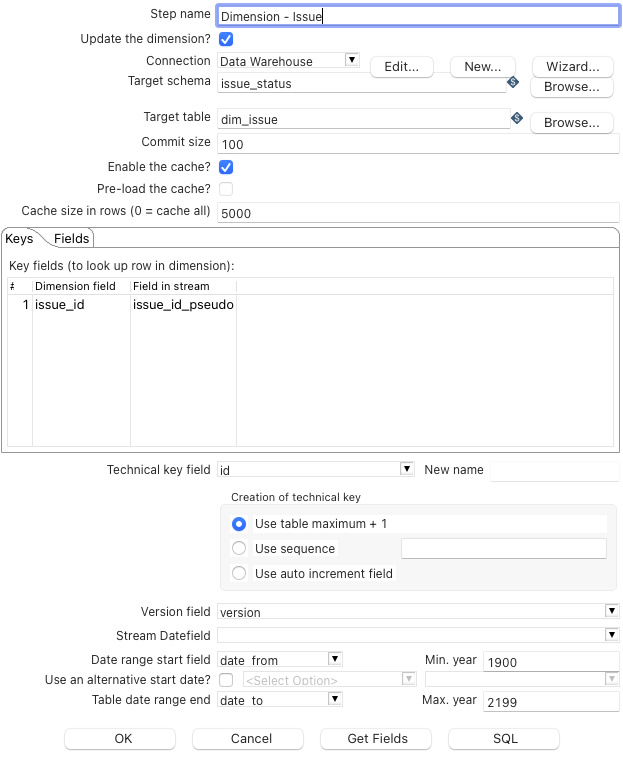
Zum zuvor erläuterten Combination lookup/update Step gibt es zwei essentielle Unterschiede.
- In der Mitte können Keys und Fields gesetzt werden, anstatt nur Fields.
- Unten kann die Versionierung konfiguriert werden.
- Es gibt keine Option für Remove lookup field?.
Die Keys dienen als eindeutiger Identifikator für die Entität, der sich nicht verändert. Das Version field gibt dem Namen des Feldes an, in dem die Version hinterlegt werden soll. Dieses wird neu erzeugt.
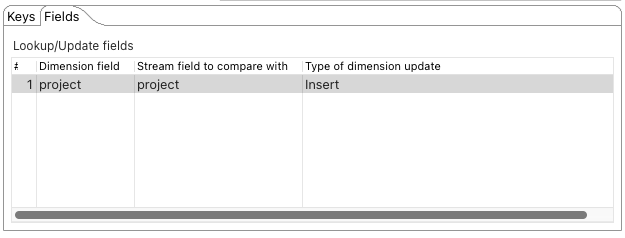
In den Fields werden alle restlichen Felder angegeben, die in die Dimensionstabelle geschrieben werden sollen.
In diesem Fall ist das nur noch project.
Wichtig ist hier jetzt Type of dimension update.
Hier wurde Insert ausgewählt.
Dadurch wird, wenn sich das Feld project im Issue verändert, ein neuer Eintrag in die Dimensionstabelle eingefügt und dieser mit der nächsten Version versehen.
Auf dieses Weise kann hier die Historie des Issues erhalten bleiben, zu welchen Projekten es gehört hat.
Da dieser Step die verwendeten Felder nicht automatisch löscht (kein Remove lookup field?), sollte dies anschließend mit einem Select values Step manuell erledigt werden.
Automatisiertes Ausführen der Jobs/Transformation#
Voraussetzung: Pentaho Server aufgesetzt
In diesem Abschnitt wird davon ausgegangen, dass sie den Pentaho Server aufgesetzt haben, wie hier beschrieben.
Sie können die Jobs und Transformationen entweder jedes Mal manuell ausführen oder sich dazu entscheiden, diese Ausführung zu bestimmten Zeitpunkten zu automatisieren (sog. Schedules einrichten).
In dieser Beschreibung wird davon ausgegangen, dass der gewünscht Job bzw. die Transformation in dem Repository des Pentaho Servers abgelegt ist (sehen Sie hier). Nur solche Jobs/Transformationen können automatisiert ausgeführt werden.
Hinweis
Im PDI Client Spoon gibt es ebenfalls die Möglichkeit, Schedules anzulegen, allerdings wurden damit einige Probleme festgestellt, weshalb dazu geraten wird, das über die Weboberfläche des Pentaho Servers zu machen. Dies ist im Folgenden beschrieben.
- Loggen Sie sich mit einem Benutzerkonto, das über ausreichende Rechte verfügt, auf der Pentaho Server Weboberfläche ein.
- Navigieren Sie zu den Dateien im Repository:
Home > Browse Files. - Klicken Sie Ihren gewünschten Job bzw. Ihre Transformation an
- und dann rechts auf
Schedule.... - Es öffnet sich ein neues Fenster, in dem Sie Ihre gewünschte Konfiguration vornehmen können.
- Anschließend überprüfen Sie, ob Ihr Schedule wie gewünscht eingerichtet wurde:
Home > Schedules.
Bereitstellen des Data Warehouses#
Voraussetzung für diese Tätigkeiten ist bereits ein aufgesetztes und für die DatenintegratorIn erreichbares DWH. Im nächsten Schritt muss der Zugriff auch mind. der DatenvisualisiererIn ermöglicht werden, damit sie die Daten in dem DWH zur Analyse nutzen kann.
Dazu könnte für jedes Schema ein User angelegt werden, dem die Lese-Rechte für dieses Schema gewährt werden. Dies kann z. B. ebenfalls mit einem Datenbankadministrationstool wie Dbeaver realisiert werden.
Process Mining (CSV-Datei)#
Für die hier eingesetzten Process Mining Werkzeuge (Disco und ProM) werden CSV-Dateien als Eingabe der Daten benötigt. Hier wird beschrieben, wie eine solche CSV-Datei mit Hilfe der bereits oben beschriebenen Spoon Transformation erzeugt werden und wie diese anschließend der DatenvisualisiererIn automatisiert zur Verfügung gestellt werden kann.
Erstellen eines Datasets#
Wenn die Daten im Data Warehouse nicht verändert werden, dann kann als Grundlage für das Dataset die flache Tabelle genutzt werden, bevor die Daten während des Transformierens für das Laden vorbereitet, also auf die Fakten- und Dimensionstabellen aufgeteilt, werden.
Der Data Stream könnte an dieser Stelle abgezweigt werden.
Ist kein Zeitstempel mehr vorhanden, so ist es ratsam diesen aus den jeweiligen Spalten (z. B. Year, Month, Day, Hour, Minute, Second) in einem einheitlichen Format zu aggregiert, bevor die Daten als z. B. Datei exportiert werden (Concat fields Step).
In Abhängigkeit des einzusetzenden PM-Werkzeugs, muss diese (erweiterte) flache Tabelle zum Beispiel als CSV-Datei bereitgestellt werden (Text file output Step).
Andernfalls (die Daten werden nach dem Laden im Data Warehouse verändert), muss ein Dataset in der Form einer flachen Tabelle aus dem Data Warehouse extrahiert und z. B. als CSV-Datei gespeichert werden. Dies kann ebenfalls mit Spoon mit einer gesonderten Transformation erfolgen.
Außerdem können die vorliegenden Daten vor dem Einlesen in ein PM-Werkzeug weiter gefiltert werden (z. B. mit Spoon, einem Tabellenkalkulationswerkzeug oder Skripten), um nur benötigte Daten zu betrachten und spätere Filterung im Werkzeug zu verringern.
Wenn Sie die Transformation sowohl auf dem Pentaho Server als auch lokal ausführen möchten (siehe oben für eine Automatisierung auf dem Server), bietet es sich an, die $DI_HOME Variable zur Spezifikation des Orts zu verwenden, an welchem die CSV abgelegt werden soll.
So müssen Sie die Transformation nicht per Hand editieren, wenn Sie die Ausführung wechseln (lokal oder Server).
- Auf dem Server (bzw. in dem Pentaho Server Docker Container) zeigt diese Variable automatisch auf das folgende Verzeichnis:
/opt/pentaho/server/pentaho-server/pentaho-solutions/system/kettle. Das wird unten bei der Bereitstellung wieder relevant. - Lokal müssen Sie diese Variable konfigurieren. Das können Sie direkt in Spoon erledigen:
Edit > Set Environment Variables ...- Name:
DI_HOME - Value: [pfad_ihres_lokalen_ordners]
Der Text file output wird dann z. B. wie folgt konfiguriert, um eine CSV Namens jira_status_star in dem Unterverzeichnis csv abzulegen:
- Filename:
${DI_HOME}/csv/jira_status_star
Bereitstellen des Datasets#
Unabhängig davon, ob die Transformation lokal oder (automatisiert) auf dem Pentaho Server ausgeführt wird, müssen die CSV-Dateien anschließend der DatenvisualisiererIn bereitgestellt werden.
Praktisch lässt sich das realisieren, indem die Dateien an geeigneter Stelle zum Download bereitgestellt werden. Bei potenziell mehreren EmpfängerInnen sollte darauf verzichtet werden, die CSV-Dateien via direkter Kommunikation zu übertragen (da diese schnell über 100 MB groß werden). Hier ist eine nicht-direkte Kommunikation vorzuziehen.
Voraussetzung: File Server aufgesetzt
In diesem Abschnitt wird davon ausgegangen, dass sie den File Server aufgesetzt haben, wie hier beschrieben.
Im Folgenden wird beschrieben, wie die CSV-Dateien manuell bzw. automatisiert bereitgestellt werden können.
Lokale Ausführung
Wenn Sie die Transformationen, welche CSV-Dateien erstellen, die Sie zum Download bereitstellen wollen, lokal ausführen, müssen Sie diese Dateien in den entsprechenden Ordner des oben genannten File Servers kopieren.
Einfach geht das z. B. via scp.
scp [ihre_csv_datei] [user_ihres_hosts]@[ip/domain_ihres_hosts]:/var/opt/docker/data_warehouse/volumes/files/csv/
Anschließend sollten Sie diese Datei z. B. über einen Browser herunterladen können: https://[ihre_domain]/downloads/csv/.
Ausführung auf dem Pentaho Server
Wenn Sie die Transformation auf dem Pentaho Server ausführen, müssen die CSV-Dateien aus dem laufenden Container in den File Server kopiert werden (beachten Sie die Erläuterung zur $DI_HOME Variable oben).
docker cp [pentaho_server_contaienr]:/opt/pentaho/server/pentaho-server/pentaho-solutions/system/kettle/csv/[ihre_csv_datei] /var/opt/docker/data_warehouse/volumes/files/csv/
Dieser Prozess lässt sich vollständig automatisieren. Wenn Sie z. B. bereits eine Transformation automatisiert ausführen, wie oben beschrieben, dann müssen Sie sich nach der Konfiguration der folgenden Schritte nicht mehr selbst darum kümmern, dass aktuelle CSV-Dateien zum Download bereitstehen.
Dazu legen Sie ein Bash-Script an (hier wird es in dem pentaho Ordner abgelegt) und führen dies anschließend mittels eines Cronjobs aus.
cd /var/opt/docker/pentaho
mkdir -p production/scripts
touch production/scripts/copy_csv_files_from_pentaho_to_download.sh
chmod u+x production/scripts/copy_csv_files_from_pentaho_to_download.sh
#!/bin/bash
# copy files
docker cp [pentaho_server_container]:/opt/pentaho/server/pentaho-server/pentaho-solutions/system/kettle/csv /var/opt/docker/data_warehouse/volumes/files/
chmod -R 755 /var/opt/docker/data_warehouse/volumes/files/
# tidy up
docker exec [pentaho_server_container] rm -rf /opt/pentaho/server/pentaho-server/pentaho-solutions/system/kettle/csv
find /var/opt/docker/data_warehouse/volumes/files/* -mtime +1 -exec rm {} \;
- kopiert alle Dateien aus dem
$DI_HOME/csvOrdner des Pentaho Server Containers in das auf dem Host gemappten Volume des File Servers, - passt die Rechte für die kopierten Dateien an,
- löscht die CSV-Dateien anschließend im Pentaho Server Container
-
und löscht dann alle Dateien in
/var/opt/docker/data_warehouse/volumes/files/, die älter als 1 Tag sind. -
Vergewissern Sie sich, dass das Script Ihren Vorstellungen entspricht, führen Sie dieses aus und kontrollieren Sie anschließend das Ergebnis.
Zur Automatisierung führen Sie dieses Script mittels Cronjob passend zu dem oben gewählten Schedule (automatisierte Ausführung der Transformation) aus. Bedenken Sie dabei, dass die Transformationen eine Ausführungszeit haben. Wenn die Transformation z. B. alle sechs Stunden ab 6 Uhr morgens ausgeführt wird und auf jeden Fall weniger als 15 Minuten läuft, könnte es sinnvoll sein, einen Cronjob alle sechs Stunden ab 6:15 Uhr auszuführen.
- Öffnen Sie die Cronjobs, als ein Benutzer mit ausreichenden Rechten, in einem Editor
- und fügen Sie folgende Zeile ein